Performing a technical SEO audit
What to watch for in the fundamentals of website architecture
A technical SEO audit should be the start of every check you do for a customer or prospect. Search engines have been attributing increasingly more weight at the technical specs in their algorithms over the last few years. More and more online marketeers are beginning to realize that a sound SEO project starts with clean and sleek website architecture. It is therefore a pity that many agencies don’t pay enough attention to this stage.
- Read more: The rise of the technical marketers
Why the technical elements of a website matters to SEO
Search engines – and Google in particular – take over 200 elements into consideration to determine the position of a website in the SERP. It is pretty useless to write great content if the bots are unable to properly crawl your blog or website. Online marketing agencies often struggle to keep an overview on the process of web building. Either they lack senior technical people or they outsource this stage of the process. To meet tight deadlines they purchase and use WordPress, Drupal or Magento themes without thinking about the longer term. This is specifically true about SEO where tangible results are sometimes only visible after a few months. Keeping an eye on the entire process from prospecting, web building, over graphic design right until copy writing is challenging and more time consuming but these efforts will bear fruit on the longer term.
In this article, we present you some important technical topics to watch for. They will help you whenever you have to do a quick SEO check. There is a lot of great software available out there, both free and paid. They offer a wide range of site analyzers and SEO toolboxes but we’ll keep that overview for another blog post. You won’t have to download anything to create an SEO report that focusses strictly on technical elements.
You’ll be examining the source code of a website a lot during this tutorial so let’s get down to that first. Open your favourite browser and surf to the website you want to get a closer look at. It’s very easy to get the source code on your screen:
- Mozilla Firefox: on your keyboard, press Ctrl+U on Windows. Press Cmd+U on Mac.
- Google Chrome: on your keyword, press Ctrl+U on Windows. Press Cmd+Alt+U on Mac.
- Safari: on your keyword, press Ctrl+U on Windows. Press Cmd+Alt+U on Mac.
In most browsers you can also simply right click and choose ‘Show Page Source’. Or you can look for a ‘developer’ menu tab in your browser’s menu bar.
1. Does the website use html5 encoding?
Believe it or not but even with the third decade of the twenty-first century right around the corner, there are still websites with outdated html. Html5 has been around for some years now and its specific aim was to make it semantically better for search engines to understand. It is very easy to distinguish an html4 website from an html5 website. Simply look in the source code. At the very top you will see the doctype declaration. On outdated html4 websites you will see something like:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
...
While in the current html5 websites you will find:
<!DOCTYPE html>
<html>
<head>
...
Much cleaner, isn’t it? If you stumble upon a website with and old html4 declaration this should be an open goal to make a proposition to your prospect.
2. Does the markup use html5 tags in a consistent way?
Even if the website has a html5 document declaration is doesn’t necessarily mean it uses the appropriate tags in a consistent way. Html5 is semantically enhanced which means search engines can better distinguish the different building blocks of a webpage so they can decide which parts are more important than others. Let’s illustrate this:
<body>
<div id="header">
...
</div>
<div id="navigation">
...
</div>
<div id="article">
...
</div>
<div id="sidebar">
...
</div>
<div id="footer">
...
</div>
</body>
Nothing out of the ordinary here, right? Except that a search engine won’t be able to understand one tiny bit of this structure. The use of the right html5 tags on this same piece of code will make things clearer:
<body>
<header>
...
</header>
<nav>
...
</nav>
<article>
...
</article>
<aside>
...
</aside>
<footer>
...
</footer>
</body>
This way, search engines can understand the structure of a web page much better. They will attribute more weight to the header and the article elements and less to the aside and footer elements. This allows you to bring a lot more logic and hierarchy into your pages. You can also put your keywords in strategic places.
3. Check the markup for validation errors
Although a visitor won’t notice anything wrong in the front end while visiting a web page, it is possible that a lot of code doesn’t render as it should. Typical validation errors are identical div id’s on the same page, block level elements nested inside inline elements, missing alt tags on images and so on. Truth be told: you will rarely see a website with impeccable markup since the popular CMS systems use of plugins and extensions that increase the risk of some coding errors.
A handful of errors won’t cause problems but if you stumble upon dozens of validation errors it should be a clear warning to review the html code. Dirty markup makes it more difficult for search bots to crawl and understand your website. A lot of free tools are available online where you can run a check in the blink of an eye:
4. Does the website use microdata and structured data?
Microdata and structured data are immensely powerful tools to add underlying meaning to your html code. Schema.org provides a wide range of schemas to accomplish this. An extensive explanation of the possibilities goes beyond the scope of this blog post but we will illustrate it with an example of one of the most common applications.
It’s good to use breadcrumbs for two main reasons. They help the user to navigate quicker through a website and it gives him an idea on what sub level he actually is. Breadcrumbs are (or should be) put in a structured list:
<ul>
<li>
<a href="https://wwww.mywebsite.com">home</a>
</li>
<li>
<a href="https://www.mywebsite.com/blog">blog</a>
</li>
</ul>
Nothing wrong with this but again: a search engine won’t be able to understand it. For a bot this is just an unordered list, nothing more. Wouldn’t it be wonderful if we can make it clear to a crawler that this is a logical hierarchy with several underlying levels? That’s exactly where structured data comes into the picture. Here is the same example with Microdata markup:
<ul itemscope itemtype="http://schema.org/BreadcrumbList">
<li itemprop="itemListElement" itemscope itemtype="http://schema.org/ListItem">
<a itemprop="item" href="https://www.mywebsite.com"><span itemprop="name">home</span></a>
<meta itemprop="position" content="1" />
</li>
<li itemprop="itemListElement" itemscope itemtype="http://schema.org/ListItem">
<a itemprop="item" href="https://www.mywebsite.com/blog"><span itemprop="name">blog</span></a>
<meta itemprop="position" content="2" />
</li>
</ul>
This way, you tell a search engine what this unordered list actually is: a breadcrumb navigation. Note you can attribute a clear hierarchical position to each element. This way, the crawler can recognize the structure of your website much better. There is an additional benefit too. Your results in the SERP will show the actual breadcrumb, which can boost your positions a bit.
{kind=link}
Apart from Microdata, you can also use RDRa and JSON-LD for markup. It’s definitely worth diving into this matter because the benefits can be huge.
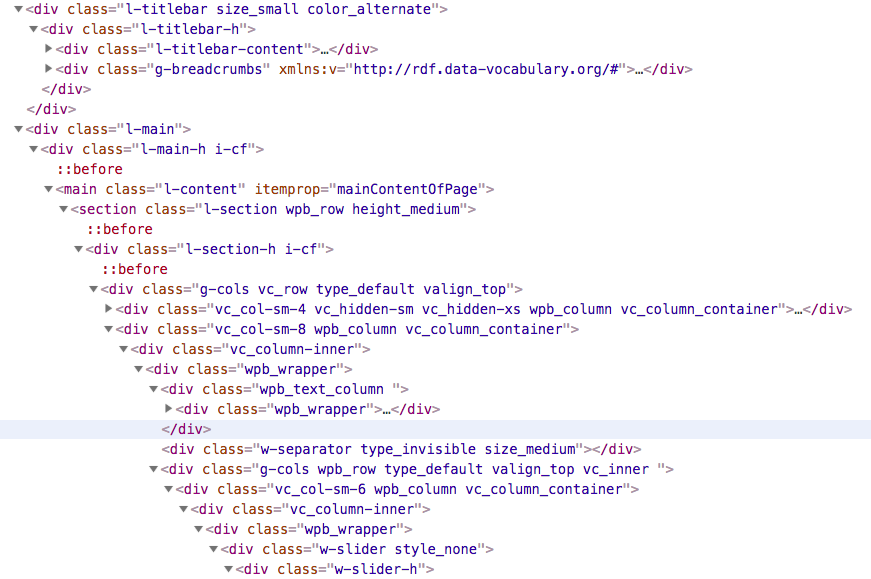
5. Is the Document Object Model (DOM) overly cluttered and complex?
It’s always best practice to keep the Document Object Model (DOM) as simple and as clean as possible. The DOM is nothing more than your actual html-code that builds the structure of your site. SEO specialists have different opinions if this topic actually matters but it’s dead simple that if your code is overly complex and heavy, it will take more time to load. And loading time is indeed a ranking factor, especially on mobile.
{kind=link}
A lot of clutter and jitter can make it difficult for bots to crawl your website. This phenomenon typically occurs with ‘drag & drop’ themes or websites that are built with visual composers in the back end. This allows you to put a website together pretty quick that might even look good. Take good care which theme you want to use. Many themes are very user friendly but can bite back if you want to optimize for SEO. Also look for deprecated techniques like inline CSS.
6. Check external resources
An absolute killer of page loading times are server requests. Every time a web page loads an external resource, it sends a request to the server. These can be external CSS files, JavaScript files and the most common: images for logos and icons. Back in the old days, logos and icons were .png files most of the time. What often happens is that dozens of these tiny files are loaded into a web page separately, thus creating a massive amount of server requests.
It’s better to use sprites for small icons so you can put them in one file so that a single server request will do. Even better is to use .svg files. This way you no longer need an external file to load. With base 64 encoding, you can put an actual string of code into your markup, eliminating the number of server requests dramatically.
7. Do a speed check, also on slower network connections
The arguments in the previous point didn’t convince you? It never hurts to do a quick speed check where you can see in detail what’s hurting the page load times. There are again numerous online tools to do so:
8. Is there any form of compression, minification or caching?
One of the results that the tools above may return is that the website is lacking compression, minification or caching. These are several techniques to reduce loading times even further. An extensive explanation – again – goes beyond the scope of this blog post but know these are also domains where you can make huge strides to reduce page load times. If you work with a common CMS, you can quickly install very reliable and free-of-charge plugins that will do the job for you.
9. Check for responsiveness or a mobile version
You got it. Even to this day there are still a lot of websites out there without a responsive lay out or a mobile version. A quick look up on your smart phone will give you the answer.
10. Check the header for noindex and nofollow meta tags
If you find the following code in the header of a home page, it should ring a bell:
<meta name="robots" content="noindex,nofollow"/>
Although there can be reasons why you don’t want search engines to index a page, this is most of the times a mistake. What this tag is saying is that the page shouldn’t be indexed and that the links shouldn’t be followed. Not good if you want your page to get up there in the SERP. This often happens when web developers put this tag in their code while the website is still in a development phase and forget to erase it when the site goes live. If you find it on the home page, there is a fair chance you will find it on any other page in the site as well. So to be short: get rid of it completely. A bot will index a page and follow links by default without the presence of such a tag.
11. Is there a 404-page and does it give the right response code?
A 404-page (page not found) is indispensable from a SEO point of view. It makes it clear to search engines that a page no longer exists so they won’t keep it in their index. That way, no one will be able to click it in the SERP, avoiding a bad user experience. You don’t want to click on a search result only to find out it’s no longer there, do you?
To accomplish this, it is also important to check if this page returns a 404 status code, otherwise it is completely useless. HTTP Status Code Checker is a very easy tool to find out.
{kind=link}
12. Does the website use https and are there mixed content issues?
It’s been a while now since Google announced to favor https websites over http in the search results. If you haven’t switched yet, you should certainly consider to do so. Even if a website uses https, you have to check for mixed content issues. These can occur when the SSL certificate isn’t installed properly or when there are some misconfigurations on the server level. It simply means the same website can be accessed through both https and http, which confuses Google. HTTP Status Code Checker is again a quick and handy tool to find out.
13. Are there canonical tags?
Canonical tags are a way to tell search engines which version of a page they have to index. This matters because you can sometimes access the same page through different urls. E.g.:
- www and non-www versions
- pages that can be accessed after conducting a search on a website
- pages with ‘clean’ permalinks (like WordPress: example.com/?p=123 vs example.com/sample-post)
By indicating to search engine which version of the page is canonical, you avoid running into duplicate content issues. Another all-time SEO killer. A canonical tag will look like this:
<link rel="canonical" href="https://www.mywebsite.com"/sample-page>
14. Does the website use clean urls?
Yep, as is the case with non-responsive websites and outdated html markup: a lot of websites still use urls that are not SEO friendly. Take the following example:
https://www.mywebsite.com/page.php?id=1234
Let’s be frank: you as a human won’t be able to find out what that page is about if you see it in the SERP, let alone a search engine. SEO friendly urls (or clean urls, permalinks) allow you to put your most important keywords for that page in the url. A benefit for both the user and the search engine:
https://www.mywebsite.com/performing-a-technical-seo-audit
13. Check the code for Google Analytics, Google Tag Manager and Google Search Console
This is easy to spot by conducting a search in the website code. Look for the following:
- UA- (for Google Analytics)
- GTM- (for Google Tag Manager)
- google-site-verification (for Google Search Console)
If you can’t find them, it is unlikely there is any kind of monitoring on the website. If you do stumble upon one of these, ask the website owner for access so you can get a broader picture of the statistics and user behaviour.
14. Is there a sitemap?
You should look for two kinds of sitemaps. First, an html sitemap in the website itself. This is for human visitors an contains an overview of all the pages in that given website. The most common place to put a link to the html sitemap is somewhere in the footer. Next, look for an xml sitemap. This one is specifically for search engines. Normally – not always – you can access this one by typing the domain followed by /sitemap.xml (e.g: mywebsite.com/sitemap.xml). The presence of an xml sitemap is good but still not enough. To really have some effect, you should submit it in Google Search Console (GSC). Look at point 13: if you can get access to that website’s property in GSC: check if this is really the case.
15. Is there a robots.txt file?
A robots.txt file is a simple text file where webmasters can indicate if certain parts or directories of a website mustn’t be crawled by search spiders (like admin folders). Similar to the xml sitemap, you can check for the presence of a robots.txt file by surfing to my website.com/robots.txt. If you happen to see that the file disallows search spiders to crawl ‘regular’ parts of the website, that’s a topic to address. Also see if there is a reference to the xml sitemap in the robots.txt file.
As is the case with the xml sitemap: you have to submit the robots.txt file in Google Search Console. So again: if you have access to GSC: check this.